


How the Big East can learn the right lessons from Sunday's snubs
It's not as simple as just running up the score, which in itself sounds easier than it is

The descent from what was the Friars 2023-24 season apotheosis Thursday night at Madison Square Garden wasn’t immediate, but by 7 p.m. on Sunday, it was complete. For perhaps 24 hours after the stirring Big East Tournament quarterfinal win, PC appeared to have catapulted Kim English’s first Friars team, depleted by injuries and unexpected roster defections, into an unlikely NCAA Tournament participant.
That sentiment changed with the updated public brackets of Friday (tracked all season at Bracket Matrix), only about a third of which had the Friars in. Then, things got darker with PC’s Big East Tournament semifinals loss to Marquette and bleaker still as results in the Pac-12, ACC, American and Mountain West Tournaments sliced down the bids available to bubble teams like the Friars.
On Sunday’s Selection Show, when CBS’ Adam Zucker revealed a First Four matchup between Virginia and Colorado State in the Midwest Region, it marked the death knell for the Friars’ chances and, indeed, the chances for all the Big East bubble teams, including Seton Hall and St. John’s.
The response to the bracketing work done by the Selection Committee was swift and furious, particularly from Big East "Twitter.” The Committee’s work was rightly derided as slipshod for myriad reasons, and two of the snubbed coaches, English and Seton Hall’s Shaheen Holloway had responses that implied that the Big East teams were unfairly omitted because of not running up the score on its weaker opponents like, say, the Big 12 had. A close look at the Teamsheets, however, reveals that running up the score isn’t particularly explanatory.
Learning the Right Lessons
If the Big East is going to be “working closely with our schools in the coming months to best position the Big East next year,” as commissioner Val Ackerman’s tepid statement indicated, then the league should make sure it’s looking at the evidence for why the league’s bubbles burst. A Tweet from Bracketologist Brad Wachtel turned my head:

Below are the Teamsheet rankings for all at-large teams in the NCAA Tournament seeded 7 or lower and a generous portion of bubble teams left out of the field. Here is what each ranking represents:
NET: sorting tool to evaluate the quality of wins by quadrants; more similar to the predictive metrics (BPI and KenPom) than the résumé-based metrics (KPI and Strength of Record).
KPI and SOR: These are the résumé-based metrics that evaluate how a team performed from a wins and losses perspective against your schedule (accounting for home/away) compared to a standard or baseline, and KPI also takes into account margin of victory via it's “percentage of points scored” factor; the first AVG after SOR is an average of those two metrics and the RK on the far left is ranking teams by that average.
BPI and KP: BPI is ESPN’s predictive metric that does take into account the margin of victory, among other factors including altitude, penalizing teams at altitude for, basically, having an unfair advantage at home (this is important for the Mountain West); KP stands for KenPom, another predictive metric and the best known one, created by college basketball stats legend (and/or reviled figure) Ken Pomeroy; AVG in this case is the average of those two rankings.
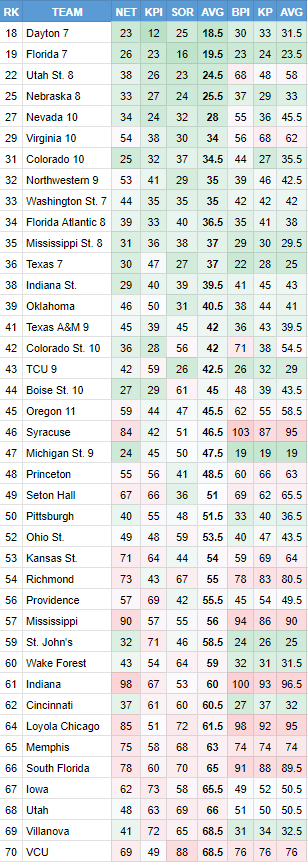
I’ve sorted by the average of the résumé-based metrics for a reason. By sorting this way, you can see why, even if the Selection Committee isn’t saying so, it decided Virginia deserved to make the field since the Cavaliers’ résumé-based metrics were so good. Moreover, you can see where the Committee may have decided they couldn’t omit a team in the top 20 in predictive metrics (Michigan State); nor could they let a team with only one Quad 1 win (Indiana State) get in the Tournament. I’m not agreeing with their decisions, just trying to understand them.
When looked at this way, it’s Oklahoma (also the team the Bracket Matrix missed on) that sticks out as the outlier snub. I’m not sure exactly what it was that kept Oklahoma out, but I expect the committee thought Oklahoma to be a cinch to make the field before everything went against bubble teams over the weekend, and then the Sooners drew the short straw (going 0-2 vs. TCU likely didn’t help). As it turned out, Colorado State was chosen over Oklahoma, due perhaps to the Q1 win advantage, who knows? The rationalization for selection at the margins is pure cherry-picking based on drivel like this from Committee Chair Charles McClelland. The top four teams left out (except Syracuse, with its outlier predictive metrics; and Princeton — maybe the committee doesn’t like orange?) were the announced first four teams left out of the field: Oklahoma, Seton Hall, Indiana State and Pittsburgh.
This analysis raises the question: if these résumé-based metrics are so important in selecting teams, how do they work? In particular, why were the Big East bubble teams’ KPIs so uniformly bad? Seton Hall’s was 66, Providence’s was 69 and St. John’s was 71. All these teams’ Strength of Record rankings alone would have put them in a better spot.
How the Résumé-based Metrics Work
Expanding on my brief definition above, KPI and Strength of Record try to ask the question: what is the quality of your results, not primarily considering by how much you won or lost (though, as noted, KPI does factor margin). They arrive at answers in very different ways, however, for two reasons:
Opponent quality: The quality of results is directly tied to the quality of the opponent, and somehow that quality must be determined. Strength of Record, an ESPN-originated metric, leans on BPI, an ESPN-originated metric, to determine how good (or bad) one’s opponents are. This is why the SOR of Mountain West teams is generally worse than their KPIs since their worse BPI makes the quality of results against those teams look worse. I couldn’t figure out what KPI is using to determine opponent quality — it isn’t NET, KenPom or BPI. Let me know if you identify it!
Weighting the value of progressively better (or worse) wins (and losses): The second key aspect here is what value you place on a given win or loss. How much more should it be worth to beat the very best team than the 25th best team, the 50th, 100th, 150th, etc.? In looking at KPI, it takes a more linear approach to this. KPI scales all wins and losses, basically, from -1 for the worst possible loss to +1 for the best possible win, adds up all your wins and losses and then divides by games played. PC’s 15-point home win over Marquette (.811) is rated its best win of the season, ahead of the 5-point, neutral court, Big East Tournament win over Creighton (.717). Providence’s three-point home win over St. John’s (.510) is its seventh-best win of the season and its seven-point neutral-court win over Georgia (.436) is its eighth-best. For an NCAA Tournament hopeful, should the gap between Creighton and Georgia on a neutral court be so small? Look at it this way, let’s say PC’s results (for the sake of argument) in the Bahamas were a seven-point win over Georgia (.436) and an eight-point win over Kansas State (.518), the latter being exactly what Miami did that weekend. The KPI for those results is .477. By defeating Georgetown by 18 (.085) and Creighton by five (again, .717) to start the Big East Tournament, PC’s KPI is .401. That seems … odd.
My conclusion from this analysis is that KPI’s curve is relatively flat, making very great wins not all that much more valuable than decent wins (say, in Quad 2), part of why PC’s four top-20 NET wins didn’t boost them as much as one would expect. Virginia and Florida Atlantic were both 8-3 in Quad 2, and Virginia got in unexpectedly while FAU got in more easily than expected with an 8 seed. At this point, St. John’s has its hand up and is saying, “Hey, but we were 6-2 in Quad 2!” My response would be that it’s not the Quad 2 record that matters; it’s how winning Quad 2-type games affects the résumé-based rankings that matter. For some reason (likely due to playing DePaul and Georgetown four times), St. John’s six Quad 2 wins didn’t boost their KPI very much. I’m not defending it, but I am trying to explain it.
I do think that if a metric like KPI is going to be used to determine suitability for selection into a field where the cutline tends to be at about the 50th best team (plus the low-major autobids), the metric should be designed for this purpose, which means that wins against the top 50 or teams close to it should be especially highly valued and very little value should be given for wins against teams outside the top 100. Instead, it seems like Virginia’s 30-point home win against Tarleton State is actually worth more than Providence’s three-point home win against St. John’s. Seriously, look it up!
We need a better understanding of how KPI works, what it’s using to determine team quality and why it’s being called a “résumé” metric when it obviously includes margin of victory.
So what, now what?
When it comes to how Big East coaches and programs should respond, I have the following recommendations:
C’mon, DePaul and Georgetown: I think the single biggest reason why the Big East bubble teams were bad in the résumé-based metrics was because of having to play these two embarrassments four times (and in PC’s case, five times). If you remove the five games Providence played against DePaul and Georgetown, PC’s KPI moves up by 12 spots. If PC just didn’t play Georgetown in the Big East Tournament, their KPI moves up two spots. Yes, Virginia played Louisville and Notre Dame a combined four times (and lost to Notre Dame), so this should have hurt them, too, but not every explanation is clean. What is clear is that getting DePaul and Georgetown into, at least, the top 150 is important. Figure it out!
Schedule wisely: The dynamic nature of college basketball makes this very hard because roster turnover makes it tricky to predict who will be good from one year to the next. That said, I caution against one popular Twitter strategy of following the Big 12 model (and you might say, the UConn model) and scheduling terrible or very good teams, destroying the terrible teams and winning enough against the great teams. That formula is hard to pull off unless you’re better than most bubble teams. Instead, I would try to schedule more opponents in the 60-150 range in the non-conference. These seem to be valued by the résumé-based rankings. If you’re not good enough to schedule top-15 programs and beat them, try to get top-150 programs instead.
Sure, run it up if you can: Running up the score on opponents is not a panacea, but it can help in three ways: First, it will make your predictive metrics look better, which can help with seeding (check out Gonzaga) and, if they’re good enough, can even get you in the Tournament (hello, Michigan State). Second, running up the score will make you a higher-quality opponent for the other teams in the conference, since the résumé-based metrics establish quality of wins by ranking teams using metrics that value point margin. So, Coach English and Coach Holloway can do each other a favor by running it up in the non-conference to bolster the impact of beating each other. Third, if the Committee is using KPI and KPI is boosting blowout wins (and, for the record, I don’t think it should), then blow people the heck out.
But More Than That
We need a better system. I’ll let St. John’s (and former Providence coach) Bob Walsh put it best:

After years of the Committee slowly getting “better” (such as that low bar is) at selecting and seeding, and becoming more predictable, which is useful in and of itself, this was a large step back. Maybe it will matter less if the Tournament does expand (gross!), but I think it’s time for a more transparent method to select and seed teams. That method need not be perfect, but it should be written down, trackable and clear. Pairwise for college hockey does this, and it seems to work fine.
For selection, a one-sheet based on something as simple as the below would be flawed but far superior than all of us watching a group of administrators who are overwhelmed by data, clutching for heuristics, and then being utterly unable to explain what they did.
At-large teams will be evaluated as follows:
Teams must have an average predictive metric ranking no worse than 80.
Teams must have at least two Quad 1 wins.
Any team with an average predictive metric ranking of 20 or better gets an at-large bid.
All other teams will be ranked based on the average of their ranking in the two résumé-based metrics.
Ties will be broken based on NET ranking.
Injuries will not be considered.
Is that a “good” system? No, I don’t think it is. But it’s much better what we have now because it’s clear, it’s transparent and it puts the goalpost in one place for everyone to see. Once the rules are written down, people can establish proper strategies — right now, we’re just guessing, and it’s infuriating.
(And one more time, seriously, what’s up with KPI? Someone needs to figure this out.)
LOVED this article. I can never find stat based articles on selection committee stuff. Always seems to just be opinion stuff which feels useless to read haha